
掌握線性回歸:分步指南

您是否想過我們如何使用機器學習根據過去的數據預測未來的結果?機器學習中使用的最基本的技術之一是線性回歸。在本文中,我們將探討線性回歸的基礎知識以及如何將其應用于解決現實世界的問題。
假設您是索道系統的所有者,該系統將游客運送到山上觀光。你想根據天氣情況和索道票價來預測每天的游客數量。
您收集有關過去一年中每一天的游客人數、每日溫度、降水量和票價的數據。然后,您可以使用線性回歸構建模型,根據天氣狀況和票價預測游客數量。
首先,您要確定自變量,在本例中為每日氣溫、降水量和票價。因變量是訪問者的數量。
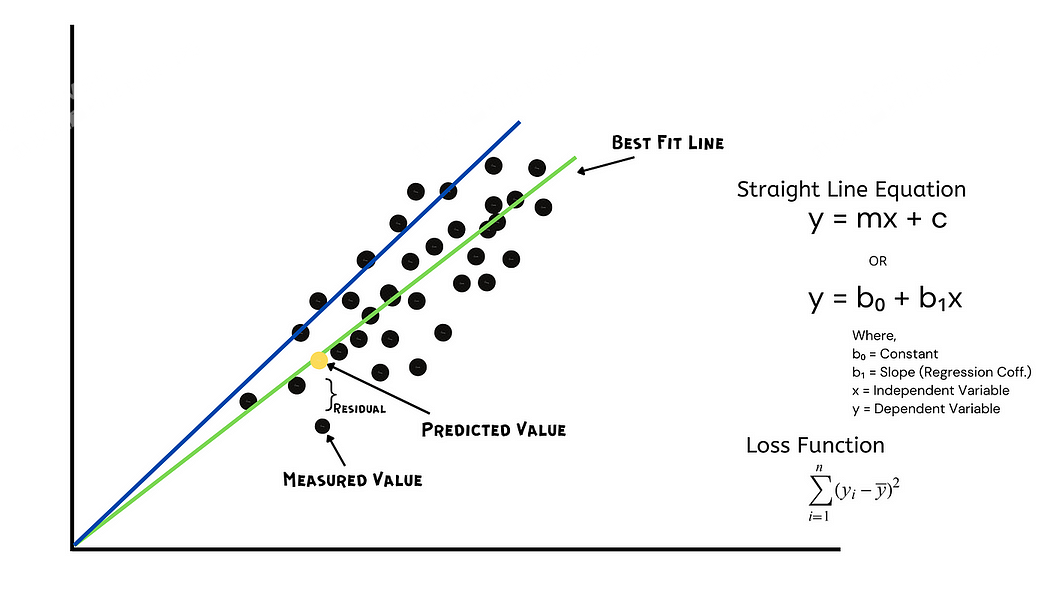
線性回歸是一種常用的統計方法,是一種預測分析。它是一種監督算法,回歸的中心思想是研究變量之間的數學關系。線性回歸有助于確定因變量(結果)與自變量(輸入)的關聯程度以及該關系的性質,無論是正還是負。我們借助最佳擬合線(也稱為回歸線)找到它們之間的關系。
一條線的方程是,y = mx + c
在這個等式中:
y 代表因變量,在這種情況下是索道的游客數量。
x 表示自變量,在本例中可以是溫度、降水量或票價。
m代表直線的斜率,它決定了自變量和因變量之間的關系。換句話說,它表示自變量每增加一個單位,因變量的變化量。
c代表y軸截距,也就是直線與y軸相交的點。
在索道示例的上下文中,方程式可以寫為:
訪客數 = m1 x 溫度 + m2 x 降水量 + m3 x 票價 + c
讓我們了解一下 Python 中線性回歸的暴力破解代碼。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# Load data into a Pandas DataFrame
df = pd.read_csv('your dataset location')
# Split data into independent and dependent variables
X = 'Your independent features'
y = 'Your dependent features'
# Create a linear regression model and fit it to the data
model = LinearRegression()
model.fit(X, y)
# Use the model to make predictions
new_data ='Your transformed data'
predicted_visitors = model.predict(new_data)
# Create a scatter plot of actual visitors versus predicted visitors
plt.scatter(y, model.predict(X))
plt.scatter(predicted_visitors, predicted_visitors, color='red')
plt.xlabel('your actual labels ')
plt.ylabel('your Predicted labels')
plt.show()
線性回歸模型的主要假設:
線性:自變量和因變量應呈線性關系,這樣自變量的變化將導致因變量按比例變化。
無多重共線性:實際值與預測值之間的差異對于自變量的所有水平應呈正態分布(數據應在多個維度上服從正態分布)。
正態性:回歸模型的誤差應該在零附近呈正態分布。
同方差性:因變量的可變性在自變量的所有值之間是一致的。
選型技巧:
逐步回歸:逐步回歸有兩種類型:向前選擇和向后淘汰。
前向選擇:此方法從一個不包含變量的模型開始,并根據變量的重要性一次添加一個變量。在每一步中,將對模型擬合提供最大改進的變量添加到模型中,直到沒有更多變量可以改進擬合為止。
逆向淘汰:此方法從一個包含所有變量的模型開始,并根據變量的重要性一次刪除一個變量。在每個步驟中,從模型中刪除對模型擬合提供最小改進的變量,直到沒有更多變量可以刪除而不會顯著降低擬合
信息準則:最常用的信息準則是 Akaike 信息準則 (AIC) 和貝葉斯信息準則 (BIC),它們提供了一種根據擬合優度和使用的參數數量來比較不同模型的方法在模型中。
正則化:正則化方法,例如嶺回歸和套索回歸,在回歸方程中添加一個懲罰項,以將不太重要的變量的系數縮小到零。這有助于降低多重共線性的影響,提高模型的泛化能力。
交叉驗證:交叉驗證涉及將數據拆分為訓練集和測試集,然后評估模型在測試集上的性能。這有助于防止過度擬合并確保模型可推廣到新數據。
解釋機器學習模型結果的技術
R 平方:R 平方是一種統計量度,表示因變量中由自變量解釋的方差的比例。它的范圍從 0 到 1,值越高表示模型對數據的擬合越好。
在索道示例中,線性回歸模型的 R 平方值告訴我們游客數量的變化有多少可以用自變量(溫度、降水量和票價)來解釋。例如,如果 R 平方值為 0.8,則表示訪客數量的 80% 的變化可以由自變量解釋,而其余 20% 是由模型中未包含的其他因素引起的.
平均絕對誤差 (MAE):平均絕對誤差 (MAE) 是衡量模型實際值和預測值之間平均絕對差值的指標。在索道示例的上下文中,MAE 可用于評估線性回歸模型根據溫度、降水量和票價預測索道游客數量的效果。
均方根誤差 (RMSE):均方根誤差 (RMSE) 是用于評估回歸模型性能的另一種流行指標。它測量預測值和實際值之間的平方差的平均值的平方根。
均方誤差 (MSE):此技術計算實際值和預測值之間的平方差的平均值。它給出了誤差項中有多少方差的想法。
現實生活中的例子
交通流量分析:線性回歸可用于模擬交通流量與各種因素(例如一天中的時間、天氣狀況等)之間的關系。
運動分析:線性回歸可以成為運動分析中的有用工具,可以深入了解球員的表現并圍繞球隊管理和球員選擇做出明智的決策。
資產定價:線性回歸可用于分析各種金融變量與資產價格之間的關系。這可以幫助投資者根據他們的預期未來回報,就購買或出售哪些資產做出明智的決定
價格優化:線性回歸可用于分析產品定價與銷量之間的關系。這可以幫助公司優化他們的定價策略以最大化銷售和利潤。












